Methodology
An end-to-end framework combining topology-regularized KG construction with constrained multi-hop benchmark synthesis.
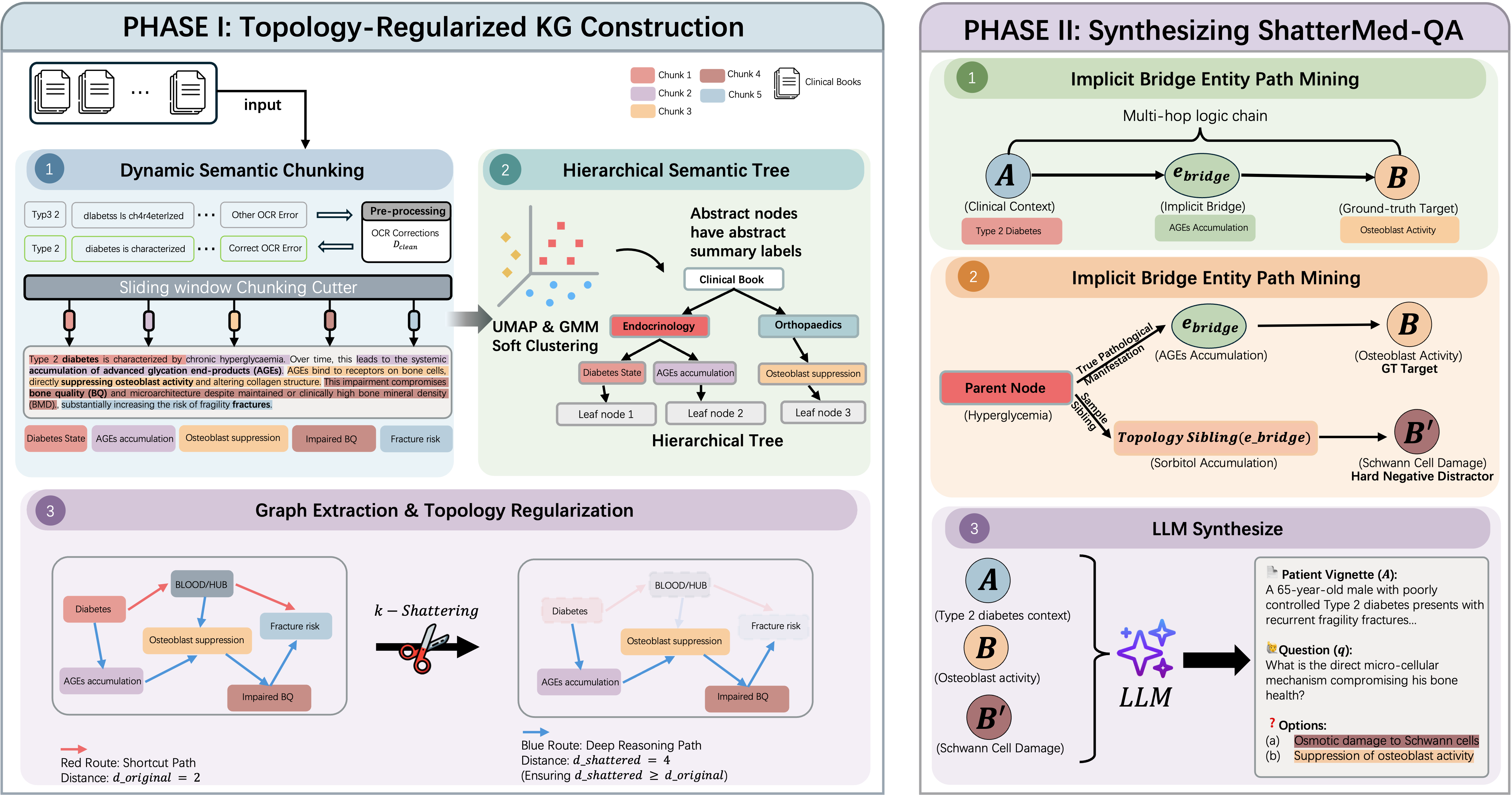
Figure 1: Overview of the ShatterMed-QA construction pipeline. Phase I builds a topology-regularized Knowledge Graph via dynamic semantic chunking, hierarchical soft clustering, and k-Shattering regularization. Phase II synthesizes multi-hop clinical questions through implicit bridge entity path mining and LLM-based vignette generation with topology-driven hard negative distractors.
Phase I: KG Construction
- Dynamic Semantic Chunking — Preserves clinical cascades using 95th-percentile cosine distance thresholds
- Hierarchical Soft Clustering — GMM + BIC optimization for overlapping medical topics
- k-Shattering Regularization — Physically prunes hub nodes ensuring dshattered(u,v) ≥ doriginal(u,v)
Phase II: QA Synthesis
- Bridge Entity Masking — The implicit bridge ebridge is strictly excluded from the vignette
- Topology-Driven Distractors — Sibling nodes sampled from the pathological hierarchy as hard negatives
- Evidence-Grounded — Every reasoning chain anchored to exact sentence-level source text